OmniMem: Scalable and Adaptive Memory Retrieval for Long Video Generation
Preprint
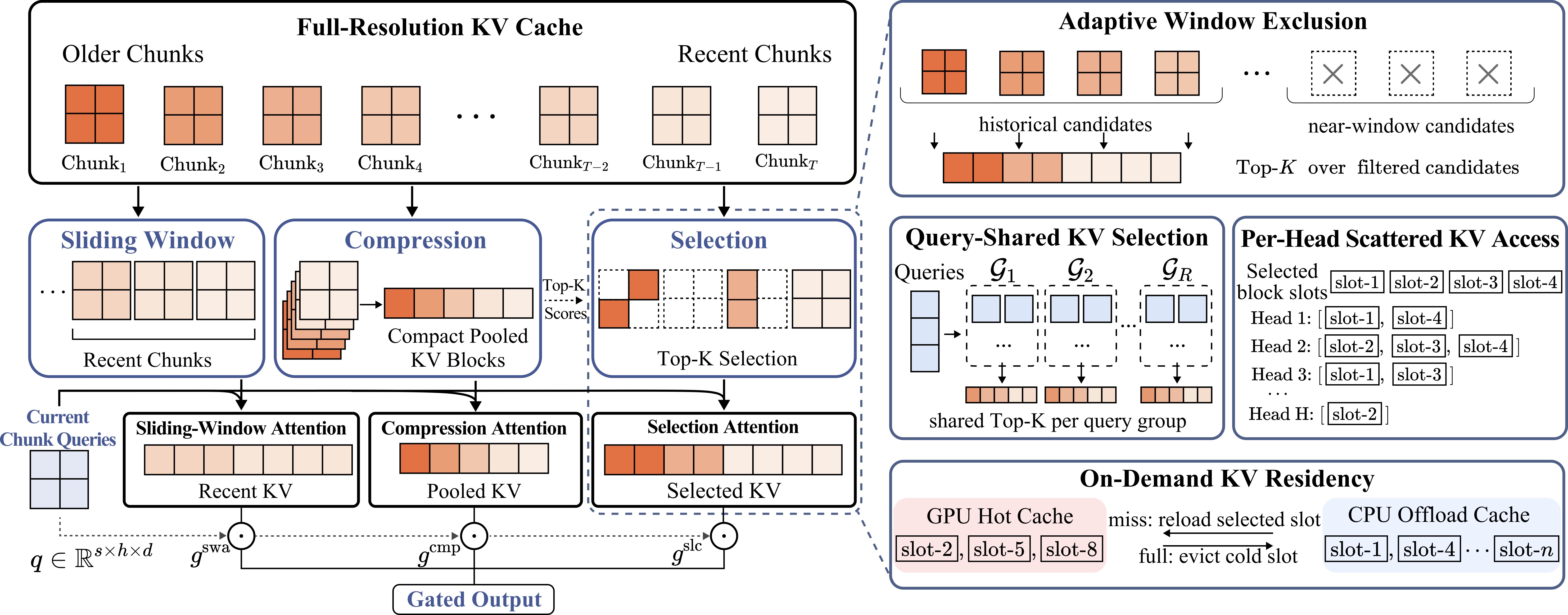
OmniMem does explicit sparse KV retrieval over the full history for autoregressive long-video generation, keeping the query-relevant details that are lost when the KV cache is truncated or compressed, and improves Dynamic Degree by 52.3% at comparable memory cost.