|
Ph.D. Candidate @ Northeastern University I am a final year PhD student in Computer Engineering at Northeastern University, under the supervision of Prof. Yanzhi Wang. My research interests focus on Efficient Generative AI, Model Compression, Hardware-Software Co-design for Efficient AI. I am on job market, and actively looking for full-time research scientist or ML engineer. Please feel free to contact me via email (wu.yushu AT northeastern.edu) if our research match. |

|
Research
|
Recent News
|
|
Taming Diffusion Transformer for Efficient Mobile Video Generation in Seconds
Yushu Wu*, Yanyu Li,*, Anil Kag, Ivan Skorokhodov, Willi Menapace, Ke Ma, Arpit Sahni, Ju Hu, Aliaksandr Siarohin, Dhritiman Sagar, Yanzhi Wang, Sergey Tulyakov Preprint. [paper] [project] Our optimized diffusion transformer achieves over 10FPS on an iPhone16 Pro Max, proving real‑time, high‑quality video generation on mobile is possible. We achieve this by using a compact VAE for dimension reduction, a KD‑guided, sensitivity‑aware tri‑level pruning to slim the model, and an adversarial step distillation for DiT that reducing inference to four steps. |
|
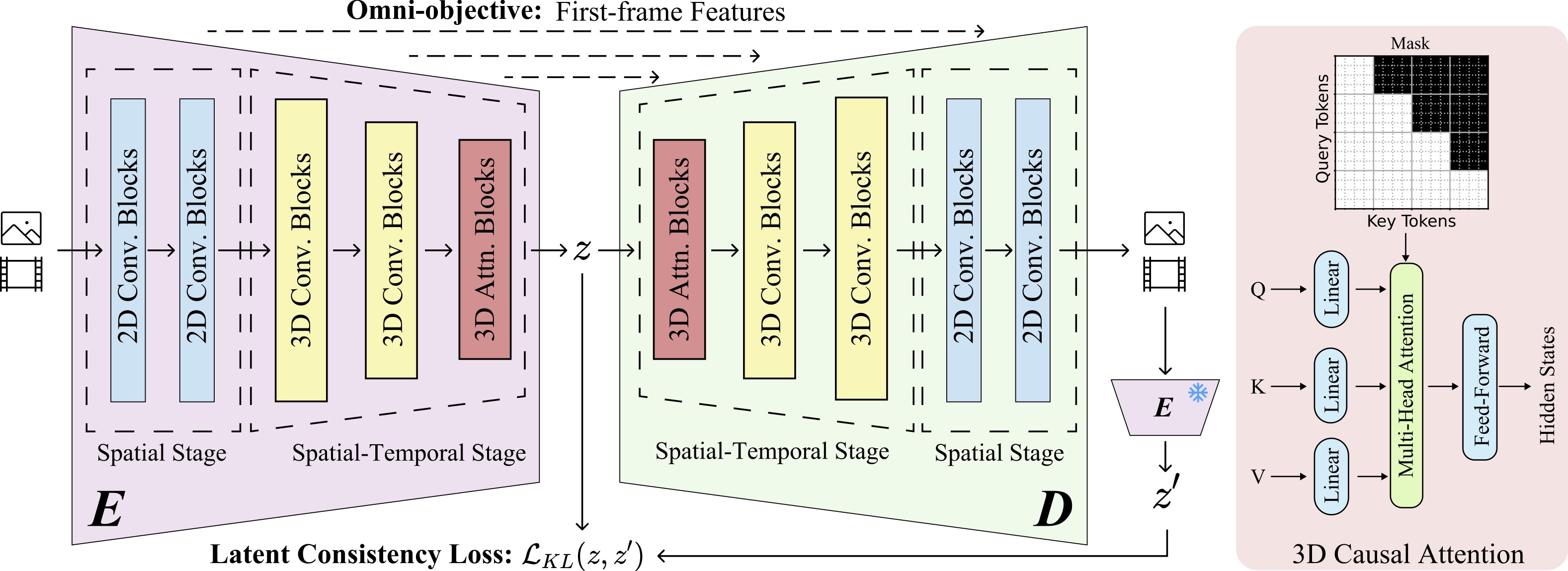
H3AE: High Compression, High Speed, and High Quality AutoEncoder for Video Diffusion
Models
Yushu Wu*, Yanyu Li*, Ivan Skorokhodov, Anil Kag, Willi Menapace, Sharath Girish, Aliaksandr Siarohin, Yanzhi Wang, Sergey Tulyakov Preprint. [paper]
TL;DR: A high-compression, high-efficient, and high-quality autoencoder for
video diffusion transformer. |
|
SnapGen-V: Generating a Five-Second Video within Five Seconds on a Mobile Device
Yushu Wu*, Zhixing Zhang*, Yanyu Li*, , Yanwu Xu, Anil Kag, Yang Sui, Huseyin Coskun, Ke Ma, Aleksei Lebedev, Ju Hu, Dimitris Metaxas, Yanzhi Wang, Sergey Tulyakov, Jian Ren Conference on Computer Vision and Pattern Recognition (CVPR), 2025. [paper] [project] We propose a comprehensive acceleration framework to bring the power of the large-scale video diffusion model to the hands of edge users. We optimize current video diffusion model architecture for mobile deployment and conduct adversarial fine-tuning algorithm for our efficient model and reduce the denoising steps to 4. Our model, with only 0.6B parameters, can generate a 5-second video on an iPhone 16 PM within 5 seconds. |
|
Fast and Memory-Efficient Video Diffusion Using Streamlined Inference
Yushu Wu*, Zheng Zhan*, Yifan Gong, Zichong Meng, Zhenglun Kong, Changdi Yang, Geng Yuan, Pu Zhao, Wei Niu, Yanzhi Wang Conference on Neural Information Processing Systems (NeurIPS), 2024. [paper] [github] We present a novel, training-free framework named Streamlined Inference, which leverages the temporal and spatial properties of video diffusion models to significantly reduces peak memory and computational overhead, making it feasible to generate high-quality videos on a single consumer GPU. |
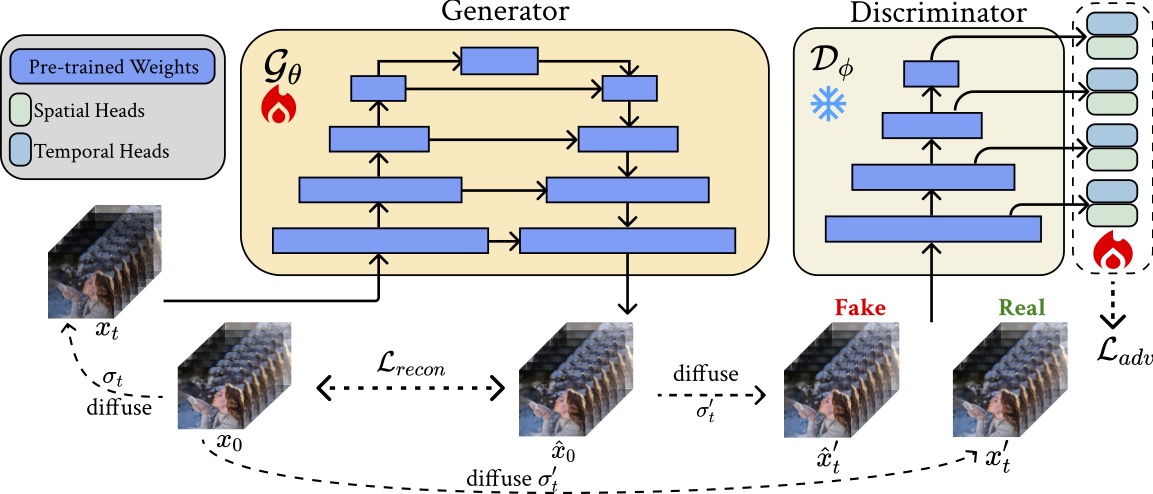
|
SF-V: Single Forward Video Generation Model
Zhixing Zhang, Yanyu Li, Yushu Wu, Yanwu Xu, Anil Kag, Ivan Skorokhodov, Willi Menapace, Aliaksandr Siarohin, Junli Cao, Dimitris Metaxas, Sergey Tulyakov, Jian Ren Conference on Neural Information Processing Systems (NeurIPS), 2024. [paper] [project] We propose a novel approach to obtain single-step video generation models by leveraging adversarial training to fine-tune pre-trained video diffusion models. We show that, multi-step video diffusion model, can be trained to perform single forward pass to synthesize high-quality videos. |
|
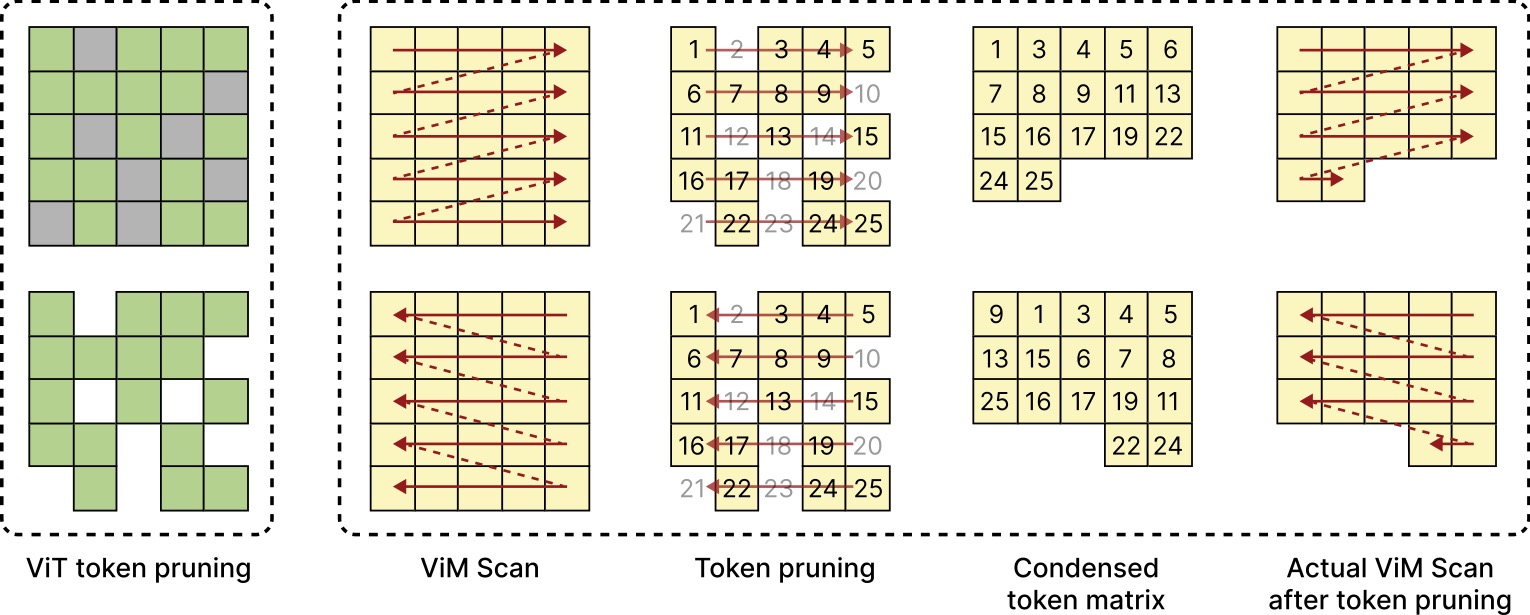
Exploring token pruning in vision state space models
Zheng Zhan*, Zhenglun Kong*, Yifan Gong*, Yushu Wu, Zichong Meng, Hangyu Zheng, Xuan Shen, Stratis Ioannidis, Wei Niu, Pu Zhao, Yanzhi Wang Conference on Neural Information Processing Systems (NeurIPS), 2024. [paper] [github] We revisit the unique computational characteristics of SSMs and discover that naive application disrupts the sequential token positions. This insight motivates us to design a novel and general token pruning method specifically for SSM-based vision models. |
|
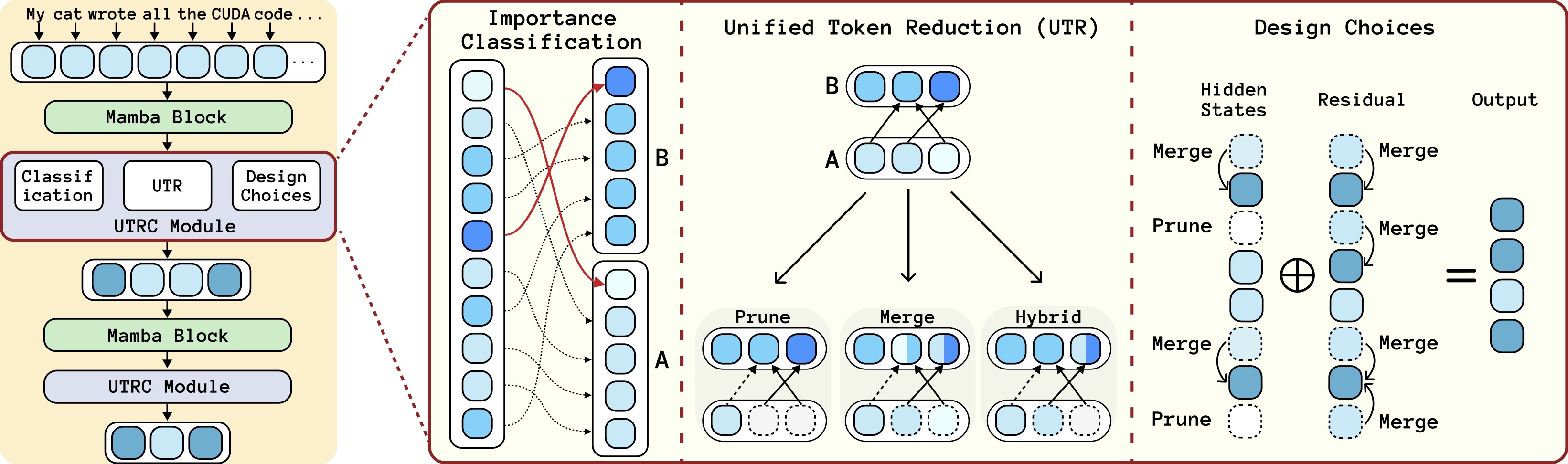
Rethinking Token Reduction for State Space Models
Yushu Wu*, Zheng Zhan*, Zhenglun Kong*, Changdi Yang, Yifan Gong, Xuan Shen, Xue Lin, Pu Zhao, Yanzhi Wang Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024. [paper] [github] We identify the reasons for this failure and the limitations of current token reduction techniques on State Space Models. We propose a tailored, unified post-training token reduction method for SSMs. |
|
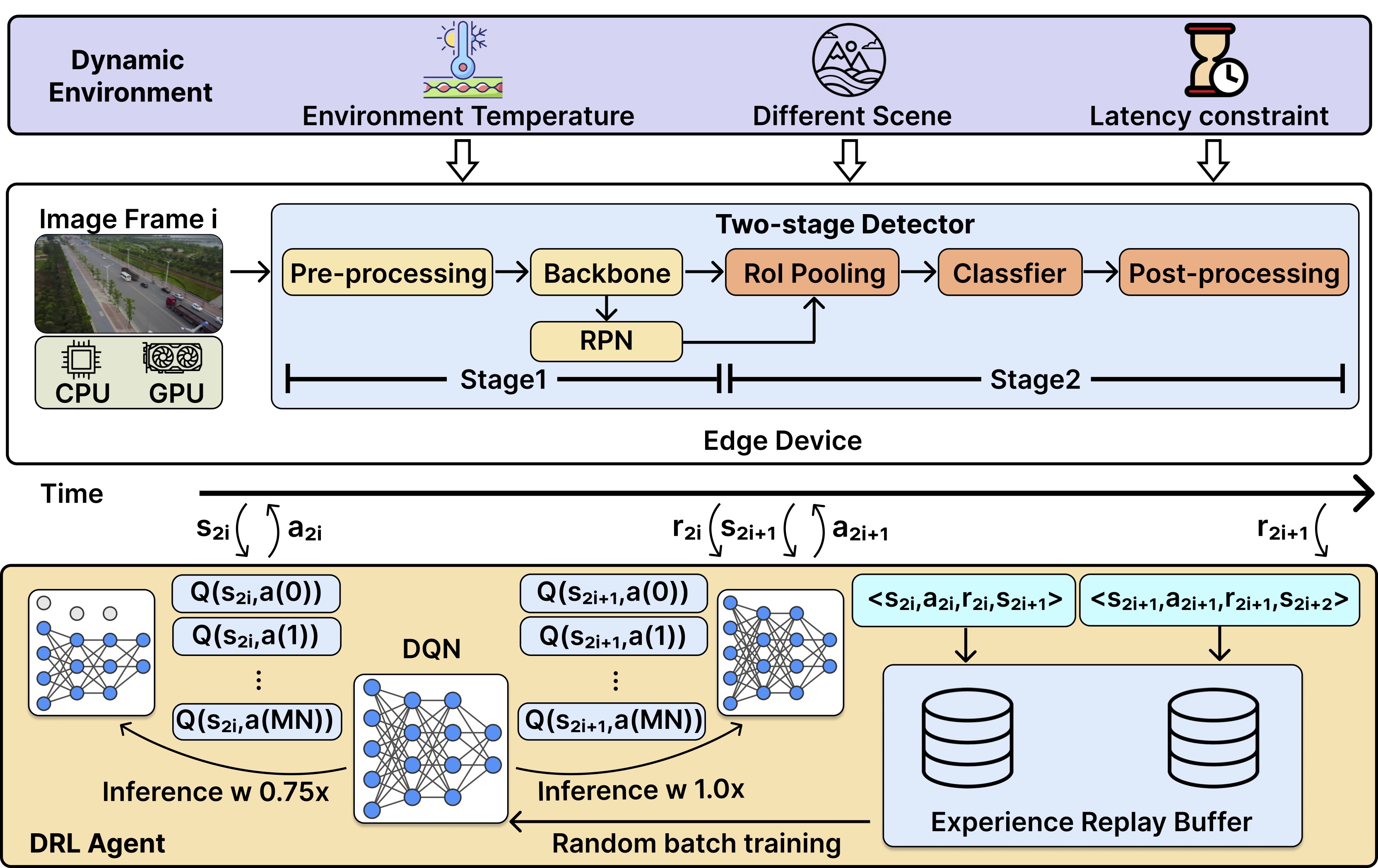
Lotus: learning-based online thermal and latency variation management for two-stage
detectors on edge devices
Yushu Wu*, Yifan Gong*, Zheng Zhan*, Pu Zhao, Liangkai Liu, Chao Wu, Xulong Tang, Yanzhi Wang Proceedings of the 61st ACM/IEEE Design Automation Conference (DAC), 2024. [paper] [github] To avoid thermal throttling and provide stable inference speed on the edge, we propose Lotus, a novel framework that is tailored for two-stage detectors to dynamicallyscale CPU and GPU frequencies jointly in an online manner based on deep reinforcement learning (DRL). |
|
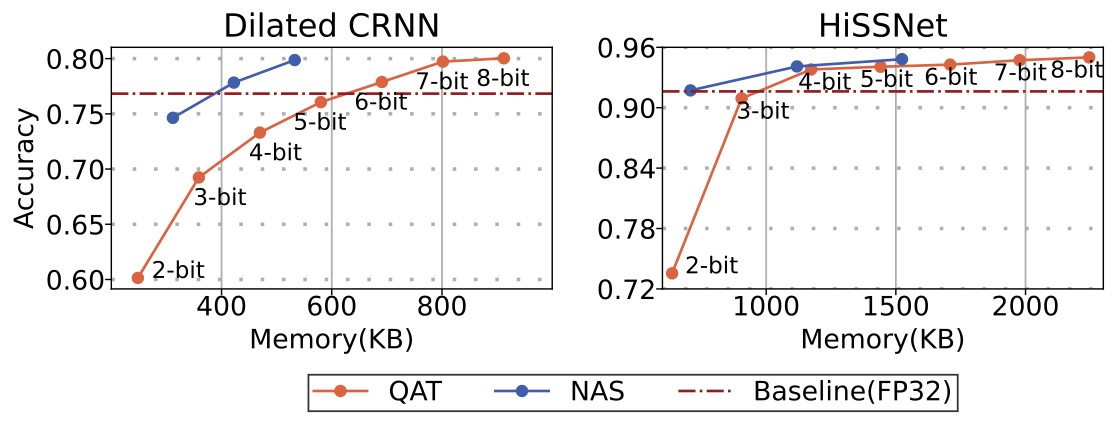
“It is Okay to be Uncommon”: Quantizing Sound Event Detection Networks on Hardware
Accelerators with Uncommon Sub-Byte Support
Yushu Wu, Xiao Quan, Mohammad Rasool Izadi, Chuan-Che Jeff Huang International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024. [paper] We identify a new class of neural network accelerators (e.g., NE16 on GAP9) that allows network weights to be quantized to different common (e.g., 8 bits) and uncommon bit-widths (e.g., 3 bits). Leveraging a differentiable NAS framework, the optimal bit-widths of a network is obtained for memory and energy efficient inference. |
|
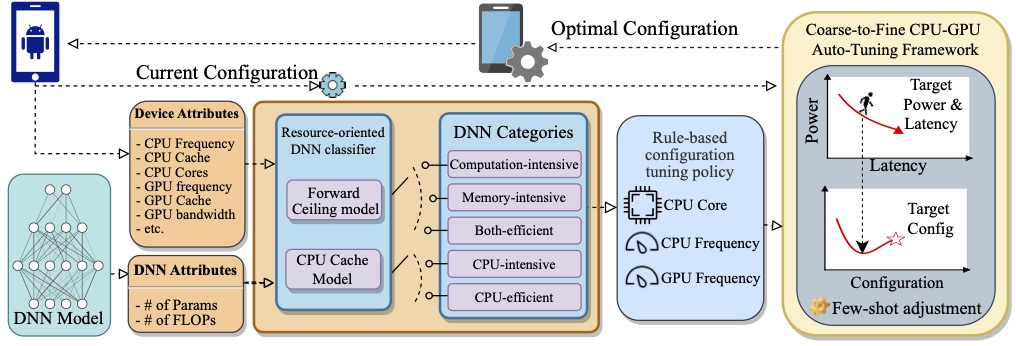
DACO: Pursuing Ultra-low Power Consumption via DNN-Adaptive CPU-GPU CO-optimization on
Mobile Devices
Yushu Wu, Chao Wu, Geng Yuan, Yanyu Li, Weichao Guo, Jing Rao, Xipeng Shen, Bin Ren, Yanzhi Wang Design, Automation and Test in Europe Conference and Exhibition (DATE), 2024. [paper] We propose DACO to reduce the power consumption of DNNs on mobile. A resource-oriented classifier is proposed to quantify the computation/memory intensity of DNN models and classify them accordingly. A set of rule-based policies is conducted for achieving the best-suited CPU-GPU system configuration. |
|
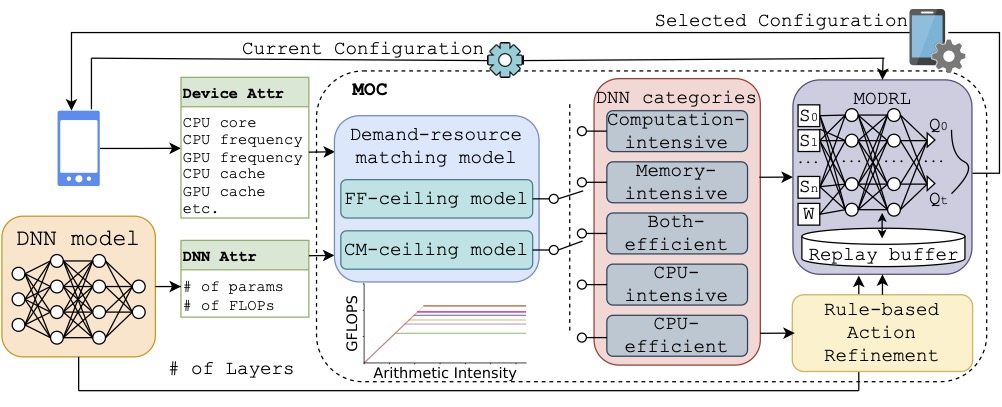
MOC: Multi-Objective Mobile CPU-GPU Co-optimization for Power-efficient DNN Inference
Yushu Wu*, Yifan Gong*, Zheng Zhan, Geng Yuan, Yanyu Li, Qi Wang, Chao Wu, Yanzhi Wang International Conference on Computer Aided Design (ICCAD), 2023. [paper] We propose MOC, a Multi-Objective deep reinforcement learning-assisted DNN inference stage-adaptive CPU-GPU Co-optimization approach to reduce the power consumption of DNN inference meanwhile delivering an excellent speed on mobile devices. |
|
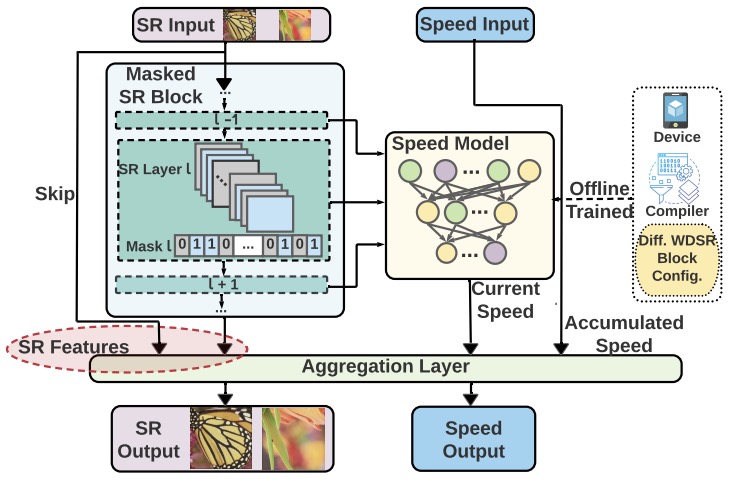
Compiler-Aware Neural Architecture Search for On-Mobile Real-time
Super-Resolution
Yushu Wu*, Yifan Gong*, Pu Zhao, Yanyu Li, Zheng Zhan, Wei Niu, Hao Tang, Minghai Qin, Bin Ren, Yanzhi Wang European Conference on Computer Vision (ECCV), 2022. [paper] [code] We propose a compiler-aware SR neural architecture search (NAS) framework that conducts depth search and per-layer width search with adaptive SR blocks. A speed model incorporated with compiler optimizations is leveraged to predict the inference latency of the SR block with various width configurations for faster convergence. |
|
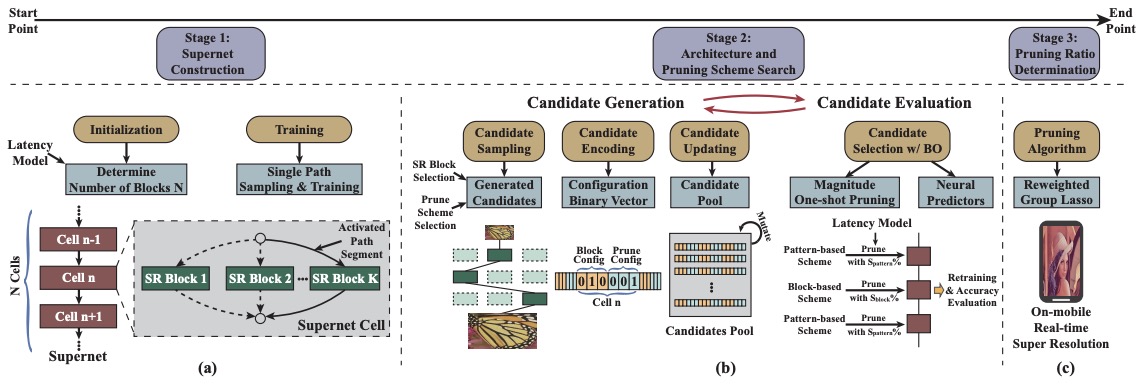
Achieving on-Mobile Real-Time Super-Resolution with Neural Architecture and Pruning
Search
Zheng Zhan*, Yifan Gong*, Pu Zhao*, Geng Yuan, Wei Niu, Yushu Wu, Tianyun Zhang, Malith Jayaweera, David Kaeli, Bin Ren, Xue Lin, Yanzhi Wang International Conference on Computer Vision (ICCV), 2021. [paper] We propose to use neural architecture search and network pruning to find a highly efficient network for image super-resolution. we are the first to achieve real-time SR inference (with only tens of milliseconds per frame) for implementing 720p resolution with competitive perceptual performance on mobile platforms. |
Work experiences
|
|
Research Intern, Epic Games, Inc. Jan 2026 - Presents, Boston, MA (Remote)Worked on World Model |

|
Research Intern, Creative Vision, Snap Inc. May 2024 - Dec 2025, Santa Monica, CAWorked on efficient text-to-video diffusion |

|
Research Intern, Bose Corporation. Jan 2023 - August 2023, Framingham, MAWorked on audio model quantization for NPU deployment |